Team Project (tP):
What
Well-written applications include error-handling code that allows them to recover gracefully from unexpected errors. When an error occurs, the application may need to request user intervention, or it may be able to recover on its own. In extreme cases, the application may log the user off or shut down the system. -- Microsoft
What
Exceptions are used to deal with 'unusual' but not entirely unexpected situations that the program might encounter at runtime.
Exception:
The term exception is shorthand for the phrase "exceptional event." An exception is an event, which occurs during the execution of a program, that disrupts the normal flow of the program's instructions. –- Java Tutorial (Oracle Inc.)
Examples:
- A network connection encounters a timeout due to a slow server.
- The code tries to read a file from the hard disk but the file is corrupted and cannot be read.
How
Most languages allow code that encountered an "exceptional" situation to encapsulate details of the situation in an Exception object and throw/raise that object so that another piece of code can catch it and deal with it. This is especially useful when the code that encountered the unusual situation does not know how to deal with it.
The extract below from the -- Java Tutorial (with slight adaptations) explains how exceptions are typically handled.
When an error occurs at some point in the execution, the code being executed creates an exception object and hands it off to the runtime system. The exception object contains information about the error, including its type and the state of the program when the error occurred. Creating an exception object and handing it to the runtime system is called throwing an exception.
After a method throws an exception, the runtime system attempts to find something to handle it in the the ordered list of methods that had been called to get to the method where the error occurredcall stack. The runtime system searches the call stack for a method that contains a block of code that can handle the exception. This block of code is called an exception handler. The search begins with the method in which the error occurred and proceeds through the call stack in the reverse order in which the methods were called. When an appropriate handler is found, the runtime system passes the exception to the handler. An exception handler is considered appropriate if the type of the exception object thrown matches the type that can be handled by the handler.
The exception handler chosen is said to catch the exception. If the runtime system exhaustively searches all the methods on the call stack without finding an appropriate exception handler, the program terminates.
Advantages of exception handling in this way:
- The ability to propagate error information through the call stack.
- The separation of code that deals with 'unusual' situations from the code that does the 'usual' work.
Exercises
Benefits of exceptions
Which are the benefits of exceptions?
- a. Exceptions allow us to separate normal code from error handling code.
- b. Exceptions can prevent problems that happen in the environment.
- c. Exceptions allow us to handle in one location an error raised in another location.
(a) (c)
Explanation: Exceptions cannot prevent problems in the environment. They can only be used to handle and recover from such problems.
When
In general, use exceptions only for 'unusual' conditions. Use normal return statements to pass control to the caller for conditions that are 'normal'.
What
Assertions are used to define assumptions about the program state so that the runtime can verify them. An assertion failure indicates a possible bug in the code because the code has resulted in a program state that violates an assumption about how the code should behave.
An assertion can be used to express something like when the execution comes to this point, the variable v cannot be null.
If the runtime detects an assertion failure, it typically takes some drastic action such as terminating the execution with an error message. This is because an assertion failure indicates a possible bug and the sooner the execution stops, the safer it is.
In the Java code below, suppose you set an assertion that timeout returned by Config.getTimeout() is greater than 0. Now, if Config.getTimeout() returns -1 in a specific execution of this line, the runtime can detect it as an assertion failure -- i.e. an assumption about the expected behavior of the code turned out to be wrong which could potentially be the result of a bug -- and take some drastic action such as terminating the execution.
int timeout = Config.getTimeout();
How
Use the assert keyword to define assertions.
This assertion will fail with the message x should be 0 if x is not 0 at this point.
x = getX();
assert x == 0 : "x should be 0";
...
Assertions can be disabled without modifying the code.
java -enableassertions HelloWorld (or java -ea HelloWorld) will run HelloWorld with assertions enabled while java -disableassertions HelloWorld will run it without verifying assertions.
Java disables assertions by default. This could create a situation where you think all assertions are being verified as true while in fact they are not being verified at all. Therefore, remember to enable assertions when you run the program if you want them to be in effect.
Enable assertions in Intellij (how?) and get an assertion to fail temporarily (e.g. insert an assert false into the code temporarily) to confirm assertions are being verified.
Java assert vs JUnit assertions: They are similar in purpose but JUnit assertions are more powerful and customized for testing. In addition, JUnit assertions are not disabled by default. We recommend you use JUnit assertions in test code and Java assert in functional code.
Resources
Tutorials:
- Java Assertions -- a simple tutorial from javatpoint.com
- Programming with Assertions (first half) -- a more detailed tutorial from Oracle
Best practices:
- Programming with Assertions (second half) -- from Oracle (also listed above as a tutorial) contains some best practices towards the end of the article.
When
It is recommended that assertions be used liberally in the code. Their impact on performance is considered low and worth the additional safety they provide.
Do not use assertions to do work because assertions can be disabled. If not, your program will stop working when assertions are not enabled.
The code below will not invoke the writeFile() method when assertions are disabled. If that method is performing some work that is necessary for your program, your program will not work correctly when assertions are disabled.
...
assert writeFile() : "File writing is supposed to return true";
Assertions are suitable for verifying assumptions about Internal Invariants, Control-Flow Invariants, Preconditions, Postconditions, and Class Invariants. Refer to [Programming with Assertions (second half)] to learn more.
Exceptions and assertions are two complementary ways of handling errors in software but they serve different purposes. Therefore, both assertions and exceptions should be used in code.
- The raising of an exception indicates an unusual condition created by the user (e.g. user inputs an unacceptable input) or the environment (e.g., a file needed for the program is missing).
- An assertion failure indicates the programmer made a mistake in the code (e.g., a null value is returned from a method that is not supposed to return null under any circumstances).
Exercises
Assertion failure in Calculator
A Calculator program crashes with an ‘assertion failure’ message when you try to find the square root of a negative number.
(c)
Explanation: An assertion failure indicates a bug in the code. (b) is not acceptable because of the word "terminated". The application should not fail at all for this input. But it could have used an exception to handle the situation internally.
Statement about exceptions and assertions
Which statements are correct?
- a. Use assertions to indicate that the programmer messed up; use exceptions to indicate that the user or the environment messed up.
- b. Use exceptions to indicate that the programmer messed up; use assertions to indicate that the user or the environment messed up.
(a)
What
Logging is the deliberate recording of certain information during a program execution for future reference. Logs are typically written to a log file but it is also possible to log information in other ways e.g. into a database or a remote server.
Logging can be useful for troubleshooting problems. A good logging system records some system information regularly. When bad things happen to a system e.g. an unanticipated failure, their associated log files may provide indications of what went wrong and actions can then be taken to prevent it from happening again.
A log file is like the flight data recorderblack box of an airplane; they don't prevent problems but they can be helpful in understanding what went wrong after the fact.

source: https://commons.wikimedia.org
Exercises
Logging vs blackbox
Why is logging like having the 'black box' in an airplane?
(a)
How
Most programming environments come with logging systems that allow sophisticated forms of logging. They have features such as the ability to enable and disable logging easily or to change the logging how much information to recordintensity.
This sample Java code uses Java’s default logging mechanism.
First, import the relevant Java package:
import java.util.logging.*;
Next, create a Logger:
private static Logger logger = Logger.getLogger("Foo");
Now, you can use the Logger object to log information. Note the use of a INFO, WARNING etc.logging level for each message. When running the code, the logging level can be set to WARNING so that log messages specified as having INFO level (which is a lower level than WARNING) will not be written to the log file at all.
// log a message at INFO level
logger.log(Level.INFO, "going to start processing");
// ...
processInput();
if (error) {
// log a message at WARNING level
logger.log(Level.WARNING, "processing error", ex);
}
// ...
logger.log(Level.INFO, "end of processing");
Resources
Tutorials:
- Java Logging API - Tutorial -- A tutorial by Lars Vogella
- Java Logging Tutorial -- An alternative tutorial by Jakob Jenkov
- A video tutorial by SimplyCoded:
Best Practices:
- 10 Tips for Proper Application Logging -- by Tomasz Nurkiewicz
- What each logging level means -- conventions recommended by Apache Project
What
A defensive programmer codes under the assumption "if you leave room for things to go wrong, they will go wrong". Therefore, a defensive programmer proactively tries to eliminate any room for things to go wrong.
Consider a method MainApp#getConfig() that returns a Config object containing configuration data. A typical implementation is given below:
class MainApp {
Config config;
/** Returns the config object */
Config getConfig() {
return config;
}
}
If the returned Config object is not meant to be modified, a defensive programmer might use a more defensive implementation given below. This is more defensive because even if the returned Config object is modified (although it is not meant to be), it will not affect the config object inside the MainApp object.
/** Returns a copy of the config object */
Config getConfig() {
return config.copy(); // return a defensive copy
}
Enforcing Compulsory Associations
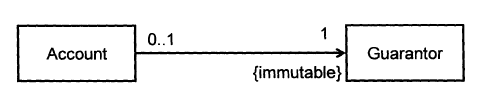
Consider two classes, Account and Guarantor, with an association as shown in the following diagram:
Example:

Here, the association is compulsory i.e. an Account object should always be linked to a Guarantor. One way to implement this is to simply use a reference variable, like this:
class Account {
Guarantor guarantor;
void setGuarantor(Guarantor g) {
guarantor = g;
}
}
However, what if someone else used the Account class like this?
Account a = new Account();
a.setGuarantor(null);
This results in an Account without a Guarantor! In a real banking system, this could have serious consequences! The code here did not try to prevent such a thing from happening. You can make the code more defensive by proactively enforcing the multiplicity constraint, like this:
class Account {
private Guarantor guarantor;
public Account(Guarantor g) {
if (g == null) {
stopSystemWithMessage("multiplicity violated. Null Guarantor");
}
guarantor = g;
}
public void setGuarantor(Guarantor g) {
if (g == null) {
stopSystemWithMessage("multiplicity violated. Null Guarantor");
}
guarantor = g;
}
…
}
Exercises
Write a Manager#addAccount()
For the Manager class shown below, write an addAccount() method that
- restricts the maximum number of Accounts to 8
- avoids adding duplicate Accounts

import java.util.*;
public class Manager {
private ArrayList<Account> theAccounts;
public void addAccount(Account acc) throws Exception {
if (theAccounts.size() == 8) {
throw new Exception("adding more than 8 accounts");
}
if (!theAccounts.contains(acc)) {
theAccounts.add(acc);
}
}
public void removeAccount(Account acc) {
theAccounts.remove(acc);
}
}
Implement Marriage
Implement the classes defensively with appropriate references and operations to establish the associations among the classes. Follow the defensive coding approach. Let the Marriage class handle the setting/removal of references.

public class Marriage {
private Man husband = null;
private Woman wife = null;
// extra information like date etc can be added
public Marriage(Man m, Woman w) throws Exception {
if (m == null || w == null) {
throw new Exception("no man/woman");
}
if (m.isMarried() || w.isMarried()) {
throw new Exception("already married");
}
husband = m;
m.enterMarriage(this);
wife = w;
w.enterMarriage(this);
}
public Man getHusband() throws Exception {
if (husband == null) {
throw new Exception("error state");
} else {
return husband;
}
}
public Woman getWife() throws Exception {
if (wife == null) {
throw new Exception("error state");
} else {
return wife;
}
}
// removal of both ends of 'Marriage'
public void divorce() throws Exception {
if (husband == null || wife == null) {
throw new Exception("no marriage");
}
husband.removeFromMarriage(this);
husband = null;
wife.removeFromMarriage(this);
wife = null;
}
}
Immutable Account class
Give a suitable defensive implementation to the Account class in the following class diagram. Note that “{immutable}” means once the association is formed, it cannot be changed.
class Account {
private Guarantor myGuarantor; // should not be public
public Account(Guarantor g) {
if (g == null) {
haltWithErrorMessage(“Account must have a guarantor”);
}
myGuarantor = g;
}
// there should not be a setGuarantor method
}
Is this defensive?
class City {
Country country;
void setCountry(Country country) {
this.country = country;
}
}
This is a defensive implementation of the association.
False
Explanation: While the design requires a City to be connected to exactly one Country, the code allows it to be connected to zero Country objects (by passing null to the setCountry() method).
Enforcing 1-to-1 Associations
Consider the association given below. A defensive implementation requires us to ensure that a MinedCell cannot exist without a Mine and vice versa which requires simultaneous object creation. However, Java can only create one object at a time. Given below are two alternative implementations, both of which violate the multiplicity for a short period of time.
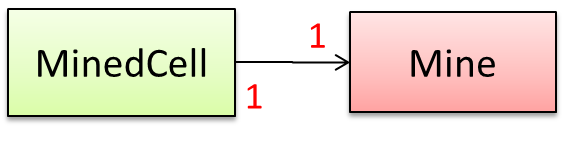
Option 1:
class MinedCell {
private Mine mine;
public MinedCell(Mine m) {
if (m == null) {
showError();
}
mine = m;
}
…
}
Option 1 forces us to keep a Mine without a MinedCell (until the MinedCell is created).
Option 2:
class MinedCell {
private Mine mine;
public MinedCell() {
mine = new Mine();
}
…
}
Option 2 is more defensive because the Mine is immediately linked to a MinedCell.
Enforcing Referential Integrity
A bidirectional association in the design (shown in (a)) is usually emulated at code level using two variables (as shown in (b)).
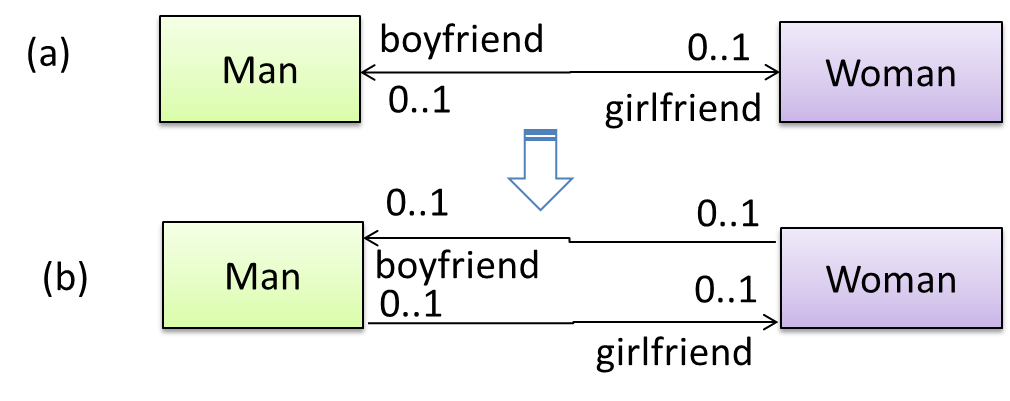
class Man {
Woman girlfriend;
void setGirlfriend(Woman w) {
girlfriend = w;
}
…
}
class Woman {
Man boyfriend;
void setBoyfriend(Man m) {
boyfriend = m;
}
}
The two classes are meant to be used as follows:
Woman jean;
Man james;
…
james.setGirlfriend(jean);
jean.setBoyfriend(james);
Suppose the two classes were used like this instead:
Woman jean;
Man james, yong;
…
james.setGirlfriend(jean);
jean.setBoyfriend(yong);
Now James' girlfriend is Jean, while Jean's boyfriend is not James. This situation is a result of the code not being defensive enough to stop this "love triangle". In such a situation, you could say that the referential integrity has been violated. This means that there is an inconsistency in object references.

One way to prevent this situation is to implement the two classes as shown below. Note how the referential integrity is maintained.
public class Woman {
private Man boyfriend;
public void setBoyfriend(Man m) {
if (boyfriend == m) {
return;
}
if (boyfriend != null) {
boyfriend.breakUp();
}
boyfriend = m;
m.setGirlfriend(this);
}
public void breakUp() {
boyfriend = null;
}
...
}
public class Man {
private Woman girlfriend;
public void setGirlfriend(Woman w) {
if (girlfriend == w) {
return;
}
if (girlfriend != null) {
girlfriend.breakUp();
}
girlfriend = w;
w.setBoyfriend(this);
}
public void breakUp() {
girlfriend = null;
}
...
}
When james.setGirlfriend(jean) is executed, the code ensures that james breaks up with any current girlfriend before he accepts jean as his girlfriend. Furthermore, the code ensures that jean breaks up with any existing boyfriends before accepting james as her boyfriend.
Exercises
Implement Player and Region
Imagine that you now support the following feature in our Minesweeper game.
Feature ID: Multiplayer
Description: A minefield is divided into mine regions. Each region is assigned to a single player. Players can swap regions. To win the game, all regions must be cleared.
Given below is an extract from our class diagram.
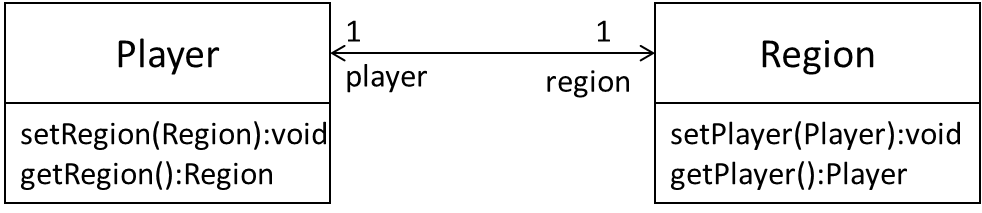
Minimally, this can be implemented like this.
class Player {
Region region;
void setRegion(Region r) {
region = r;
}
Region getRegion() {
return region;
}
}
// Region class is similar
However, this is not very defensive. For example, a user of this class can pass a null to either of the methods, thus violating the multiplicity of the relationship.
Implement the two classes using a more defensive approach. Take note of the bidirectional link which requires us to preserve referential integrity at all times.
In this solution, assume Regions can be created without Players (note that you cannot be 100% defensive all the time). The usage will be something like this:
Region r1 = new Region();
Player p1 = new Player(r1);
Region r2 = new Region();
Player p2 = new Player(r2);
p1.setRegion(r2);
r1.setPlayer(p2);
Here are the two classes. Get methods are omitted as they are simple. Note how much extra effort you need to be defensive.
public class Region {
private Player myPlayer;
public Region() {
// initialise region
}
public void setPlayer(Player newPlayer) {
if (newPlayer == null) {
stopSystemWithErrorMessage("Multiplicity violation");
}
if (myPlayer == newPlayer) {
return; // same player
}
if (myPlayer != null) {
// I already have a Player!
myPlayer.removeRegion(this);
}
myPlayer = newPlayer;
// set the reverse link
myPlayer.setRegion(this);
}
public void removePlayer(Player disconnectingPlayer) {
if (myPlayer == disconnectingPlayer) {
myPlayer = null;
} else {
stopSystemWithErrorMessage("Unknown Player trying to disconnect");
}
}
private void stopSystemWithErrorMessage(String msg) {
...
}
}
public class Player {
private Region myRegion;
public Player(Region region) {
setRegion(region);
}
public void setRegion(Region newRegion) {
if (newRegion == null) {
stopSystemWithErrorMessage("Multiplicity violation");
}
if (myRegion == newRegion) {
return; // no change in Region!
}
if (myRegion != null) {
// previous region exists
myRegion.removePlayer(this);
}
myRegion = newRegion;
// set the reverse link
myRegion.setPlayer(this);
}
public void removeRegion(Region disconnectingRegion) {
if (myRegion == disconnectingRegion) {
myRegion = null;
}
}
private void stopSystemWithErrorMessage(String msg) {
...
}
}
Note that the above code stops the system when the multiplicity is violated. Alternatively, you can throw an exception and let the caller handle the situation.
Bidirectional association between Bank and Account
Implement this bidirectional association. Note that the Bank uses the accNumber attribute to uniquely identify an Account object. Assume the Bank class is responsible for maintaining the links between objects.

The code below contains a method in the Bank class to create an account; the bank field in the new account is thereby filled by the bank creating it.
Assume that once an Account has been assigned to a Bank, it cannot be assigned to a different Bank. Once the Account is removed from the Bank, it will not be used anymore (hence, no need to remove the link from Account to Bank).
public class Account {
private int accNumber;
private Bank theBank;
public Account(int n, Bank b) {
accNumber = n;
theBank = b;
}
public int getNumber() {
return accNumber;
}
public Bank getBank() {
return theBank;
}
}
import java.util.*;
public class Bank {
private HashMap<Integer, Account> theAccounts = new HashMap<Integer, Account>();
public void createAccount(int n) {
addAccount(new Account(n, this));
}
public void addAccount(Account a) {
theAccounts.put(a.getNumber(), a);
}
public void removeAccount(int accNumber) {
theAccounts.remove(accNumber);
}
public Account lookupAccount(int accNumber) {
return theAccounts.get(accNumber);
}
}
Is the code defensive? Teacher and Student
(a) Is the code given below a defensive translation of the associations shown in the class diagram? Explain your answer.
class Teacher {
private Student favoriteStudent;
void setFavoriteStudent(Student s) {
favoriteStudent = s;
}
}
class Student {
private Teacher favoriteTeacher;
void setFavoriteTeacher(Teacher t) {
favoriteTeacher = t;
}
}

(b) In terms of maintaining referential integrity in the implementation, what is the difference between the following two diagrams?

(c) Show a defensive implementation of the remove(Member m) method of the Club class given below.

(a) Yes. Each link is mutable and unidirectional. A simple reference variable is suitable to hold the link.
The Teacher class can be made even more defensive by introducing a resetFavoriteStudent() method to unlink the current favorite student from a teacher. In that case, the setFavoriteStudent(Student) method should not accept null. This approach is more defensive because it prevents a null value being passed to setFavoriteStudent(Student) by mistake and being interpreted as a request to de-link the current favorite student from the Teacher object.
(b) First diagram has unidirectional links. Second has a bidirectional link. RI is only applicable to the second.
(c)
void removeMember(Member m) {
if (m==null) {
throw exception("this is null, not a member!");
} else if (member_count == 10) {
throw exception("we need at least 10 members to survive!");
} else if (!isMember(m)) {
throw exception("this fellow is not a member of our club!");
} else {
members.remove(m); // members is a data structure such as ArrayList
}
}
True or False?
Bidirectional associations, if not implemented properly, can result in referential integrity violations.
True
Explanation: Bidirectional associations require two objects to link to each other. When one of these links is not consistent with the other, you have a referential integrity violation.
When
It is not necessary to be 100% defensive all the time. While defensive code may be less prone to be misused or abused, such code can also be more complicated and slower to run.
The suitable degree of defensiveness depends on many factors such as:
- How critical is the system?
- Will the code be used by programmers other than the author?
- The level of programming language support for defensive programming
- The overhead of being defensive
Exercises
Defensive programming
Defensive programming,
- a. can make the program slower.
- b. can make the code longer.
- c. can make the code more complex.
- d. can make the code less susceptible to misuse.
- e. can require extra effort.
(a)(b)(c)(d)(e)
Explanation: Defensive programming requires a lot more checks, possibly making the code longer, more complex, and slower. Use it only when benefits outweigh costs, which is often.
Design by Contract
term was coined by Bertrand MeyerDesign by contract (DbC) is an approach for designing software that requires defining formal, precise and verifiable interface specifications for software components.
Suppose an operation is implemented with the behavior specified precisely in the API (preconditions, post conditions, exceptions etc.). When following the defensive approach, the code should first check if the preconditions have been met. Typically, exceptions are thrown if preconditions are violated. In contrast, the Design-by-Contract (DbC) approach to coding assumes that it is the responsibility of the caller to ensure all preconditions are met. The operation will honor the contract only if the preconditions have been met. If any of them have not been met, the behavior of the operation is "unspecified".
Languages such as Eiffel have native support for DbC. For example, preconditions of an operation can be specified in Eiffel and the language runtime will check precondition violations without the need to do it explicitly in the code. To follow the DbC approach in languages such as Java and C++ where there is no built-in DbC support, assertions can be used to confirm pre-conditions.
Exercises
Statements about the Design-by-contract approach
Which statements are correct?
- a. It is not natively supported by Java and C++.
- b. It is an alternative to OOP.
- c. It assumes the caller of a method is responsible for ensuring all preconditions are met.
(a)(b)(c)
Explanation: DbC is not an alternative to OOP. You can use DbC in an OOP solution.